
This paper presents StreamChat, a novel approach that enhances the interaction capabilities of Large Multimodal Models (LMMs) with streaming video content. In streaming interaction scenarios, existing methods rely solely on visual information available at the moment a question is posed, resulting in significant delays as the model remains unaware of subsequent changes in the streaming video. StreamChat addresses this limitation by innovatively updating the visual context at each decoding step, ensuring that the model utilizes up-to-date video content throughout the decoding process. Additionally, we introduce a flexible and efficient cross-attention-based architecture to process dynamic streaming inputs while maintaining inference efficiency for streaming interactions. Furthermore, we construct a new dense instruction dataset to facilitate the training of streaming interaction models, complemented by a parallel 3D-RoPE mechanism that encodes the relative temporal information of visual and text tokens. Experimental results demonstrate that StreamChat achieves competitive performance on established image and video benchmarks and exhibits superior capabilities in streaming interaction scenarios compared to state-of-the-art video LMMs.
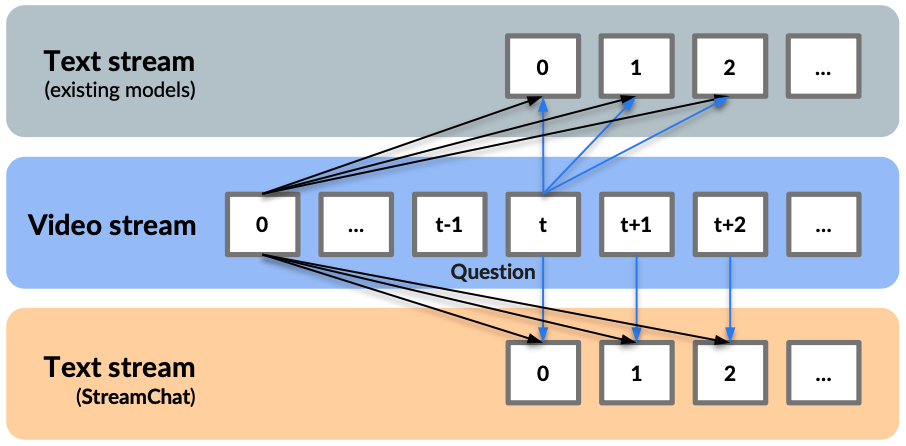
In the context of streaming video interaction, effective engagement requires LMMs to not only recognize visual content but also to track dynamic changes throughout the video. Current approaches often limit their analysis to video frames available at the moment a question is posed, neglecting significant content alterations that may occur during the response time. This delay can hinder user experience, especially in dynamic environments where timely updates are crucial.
To overcome these challenges, we introduce StreamChat, a novel method that equips LLMs with the most recent video information at each decoding step. We use a sliding window approach to update the visual context for LLM. This dynamic interaction allows for more accurate and timely responses, addressing the shortcomings of existing models.
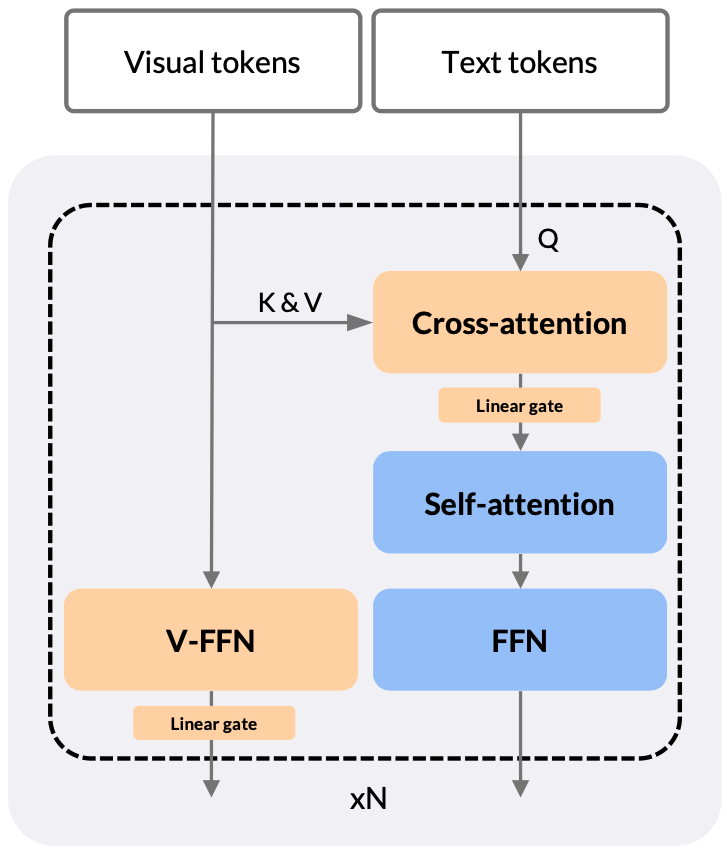
We introduce an flexible and efficient architecture based on cross-attention mechanism for connection visual inputs and LLM. The cross-attention operation is much more efficient when running at a high FPS. We also introduce some modifications to improve the final performance on benchmarks, such as V-FFN and linear gate.
During inference, we employ a parallel approach to ensure efficient. We utilize separate a thread to continuously read the video stream and store the extracted visual tokens in a First-In-First-Out (FIFO) queue. When the LLM requires decoding to generate a response, it acquires the latest video tokens from the FIFO queue. The model then incorporates this current information to decode the next token, ensuring that its responses are informed by the most up-to-date video stream context.
To better model the positional information of streaming video and text, we propose parallel 3D-RoPE that extends traditional 1D-RoPE to 3D space with a parallel arrangement of visual and text tokens. Given a text token and a visual token at the same timestamp, we apply the same temporal index for them. The parallel arrangement is crucial for the high FPS inference in the streaming setting, where the traditional arrangement may have a significant temporal positional gap between two adjacent text tokens while our approach ensures their continuity.

In addition to existing image/video instruction data, we create a new dense instruction data based on dense caption data. One dense instruction data consists of several (time interval, instruction, answer) triplets, with each word of the instruction-answer pairs annotated with a timestamp in a heuristic manner. During training, we employ attention masks to ensure that each text token can only attend to video information before its corresponding timestamp. This method effectively simulates the conditions of streaming interaction throughout the training process.
We provide a qualitative evaluation of StreamChat's capabilities on streaming video. While previous methods only answer the question using the visual context up to the moment the question is asked, StreamChat can dynamically update its visual context alongside the streaming video and adapt its answer accordingly. We show that StreamChat can better capture dynamic video content and provide more accurate answers.

To evaluate LMMs' streaming interaction capabilities, we construct a streaming evaluation benchmark from existing dense caption datasets. we use Gemini-1.5-Pro as the judge for performance evaluation. We feed the ground truth answer along with the outputs from the two models to the judge and ask the judge to determine which model's answer is better.
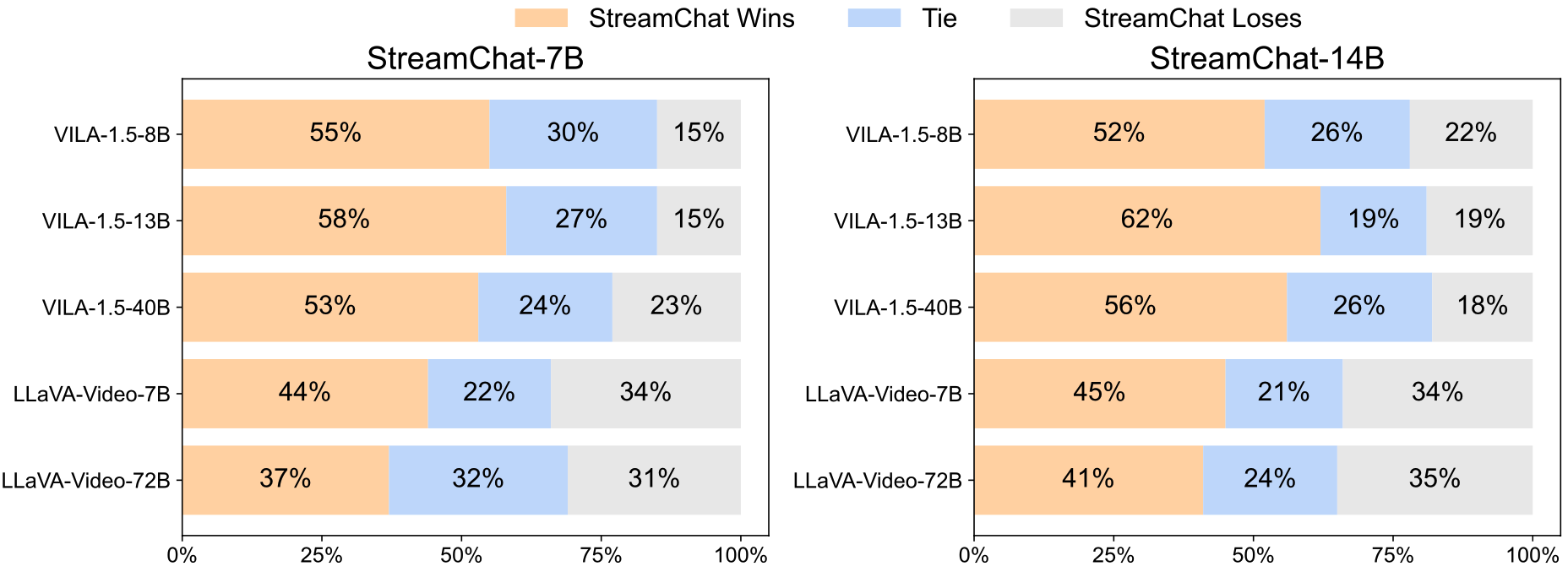
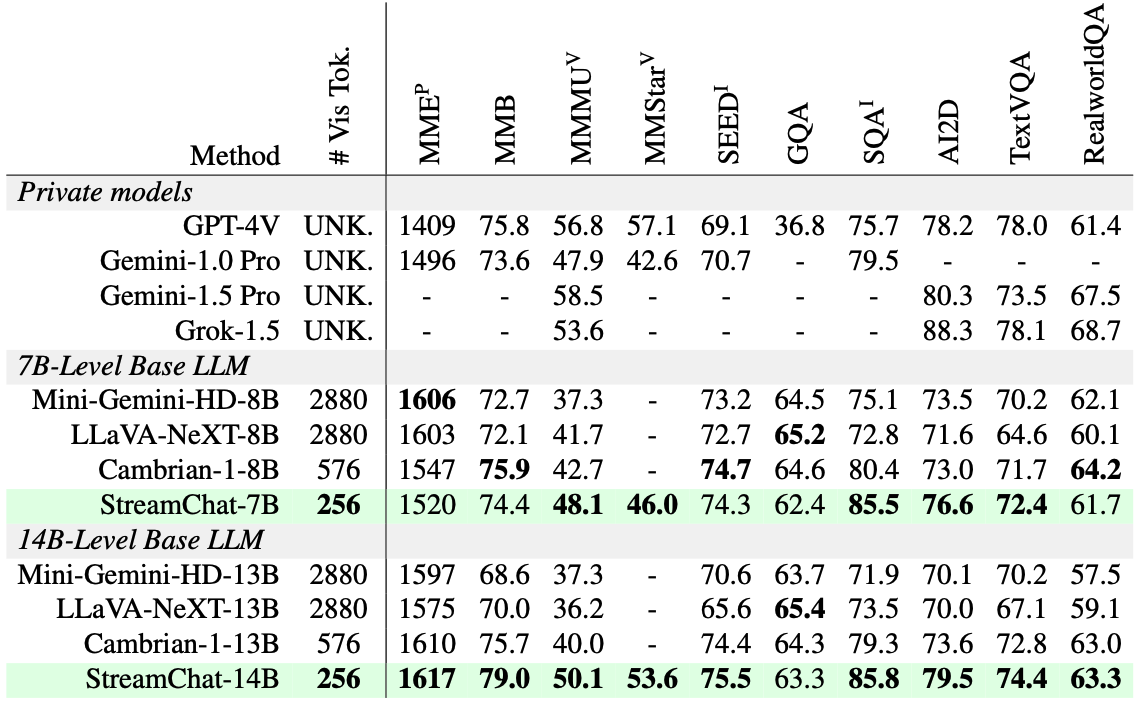
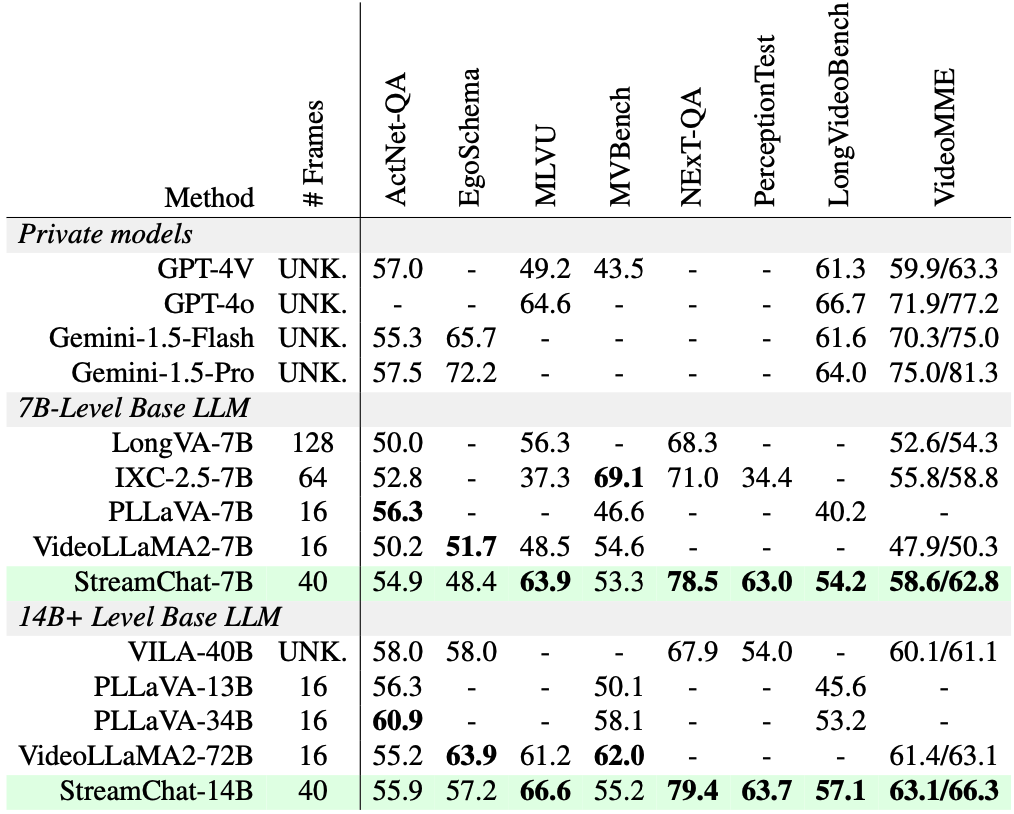
We also demonstrate that StreamChat achieves competitive performance on existing image and video benchmarks.
@article{liu2024streamchat,
title={StreamChat: Chatting with Streaming Video},
author={Jihao Liu and Zhiding Yu and Shiyi Lan and Shihao Wang and Rongyao Fang and Jan Kautz and Hongsheng Li and Jose M. Alvare},
year={2024},
eprint={2412.08646},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.08646},
}