|
I am a PhD student in Multimedia Lab (MMLab), department of Electronic Engineering at the Chinese University of Hong Kong, supervised by Prof. Hongsheng Li.
Email / Google Scholar / Twitter / Github |

|
|
My recent research focuses on real-time multimodal models, integrating streaming video and audio with LLM. Previously, I have worked on large-scale pretraining, knowledge distillation, and developing instruction-following large multimodal models. |
|
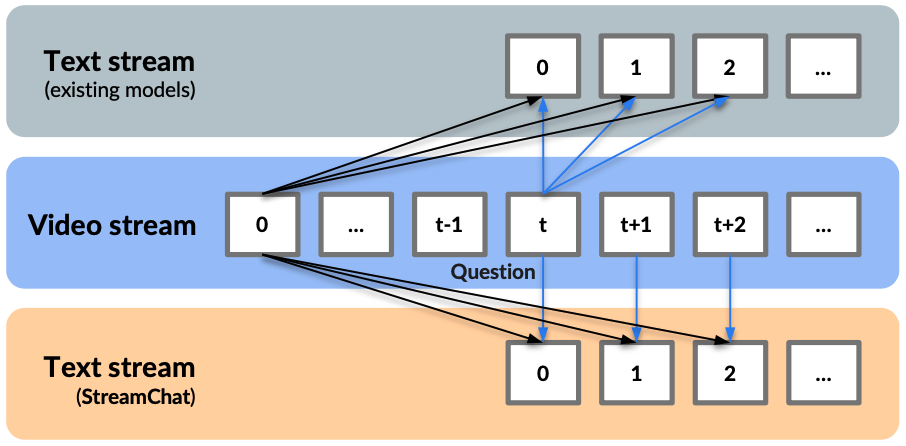
Jihao Liu, Zhiding Yu, Shiyi Lan, Shihao Wang, Rongyao Fang, Jan Kautz, Hongsheng Li, Jose M. Alvarez Arxiv, 2024 project page / arxiv We introduce StreamChat, a novel Large Multimodal Model that can interact with streaming video smoothly. |
|
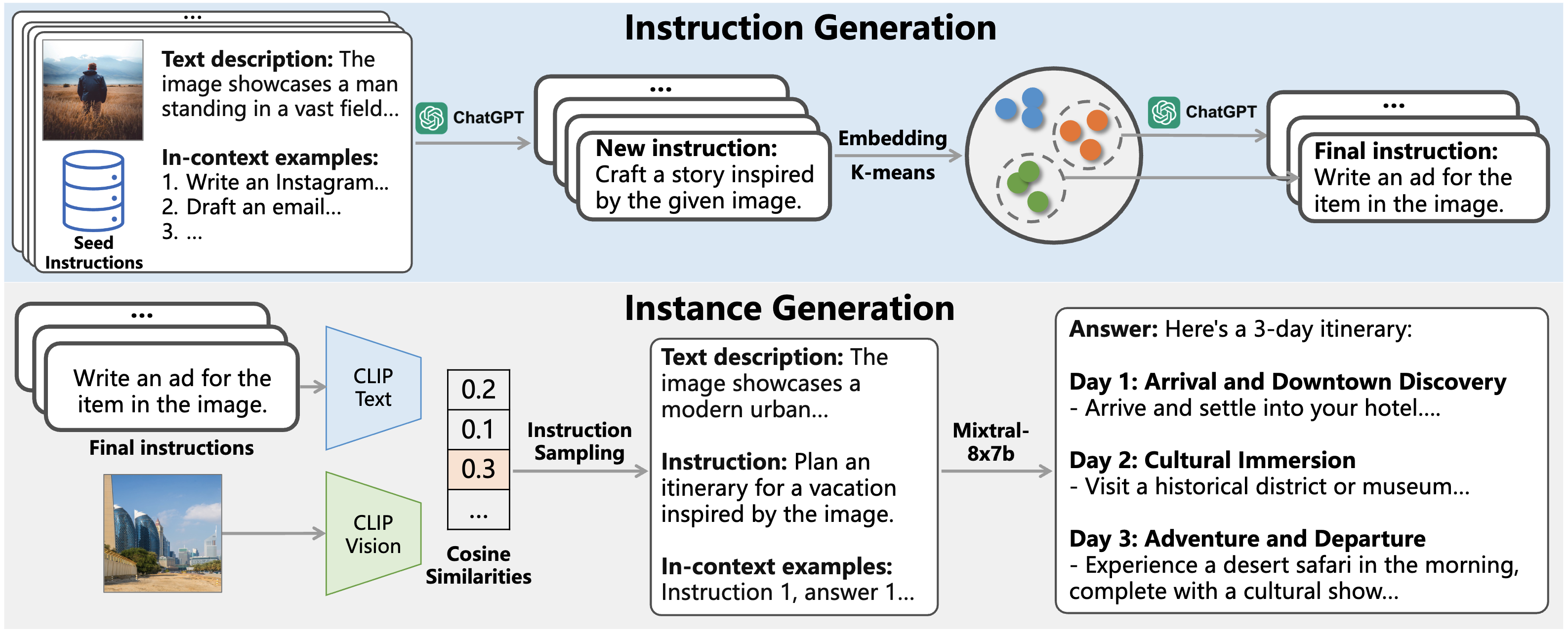
Jihao Liu, Xin Huang, Jinliang Zheng, Boxiao Liu, Jia Wang, Osamu Yoshie, Yu Liu, Hongsheng Li Arxiv, 2024 arxiv / code / data We introduce MM-Instruct, a large-scale dataset of diverse and high-quality visual instruction data designed to enhance the instruction-following capabilities of large multimodal models (LMMs). |
|
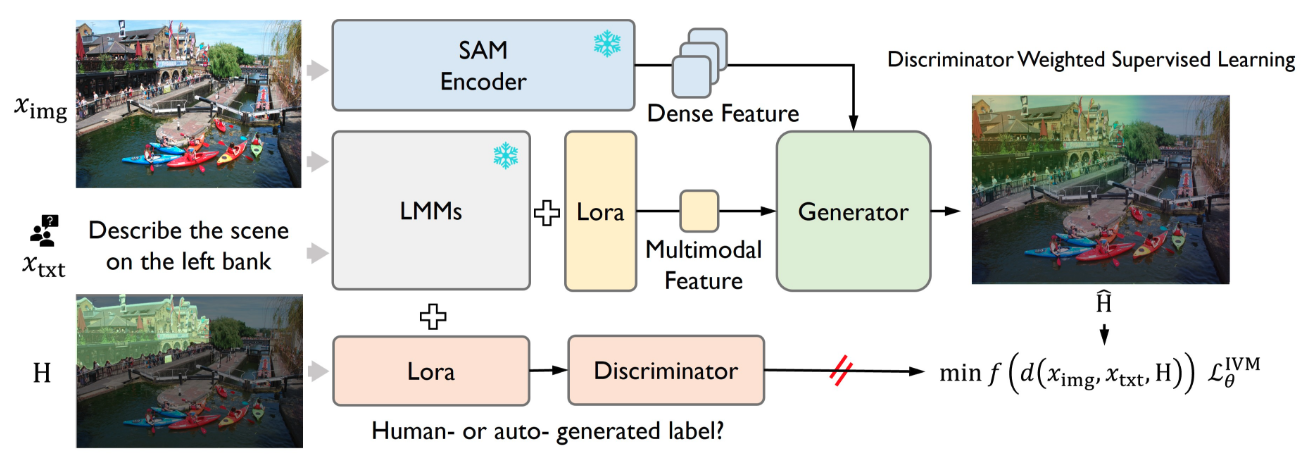
Jinliang Zheng, Jianxiong Li, Sijie Cheng, Yinan Zheng, Jiaming Li, Jihao Liu, Yu Liu, Jingjing Liu, Xianyuan Zhan Arxiv, 2024 arxiv / code IVM is a new versatile visual grounding model that is compatible with diverse multimodal models, such as LMM and robot model. |
|
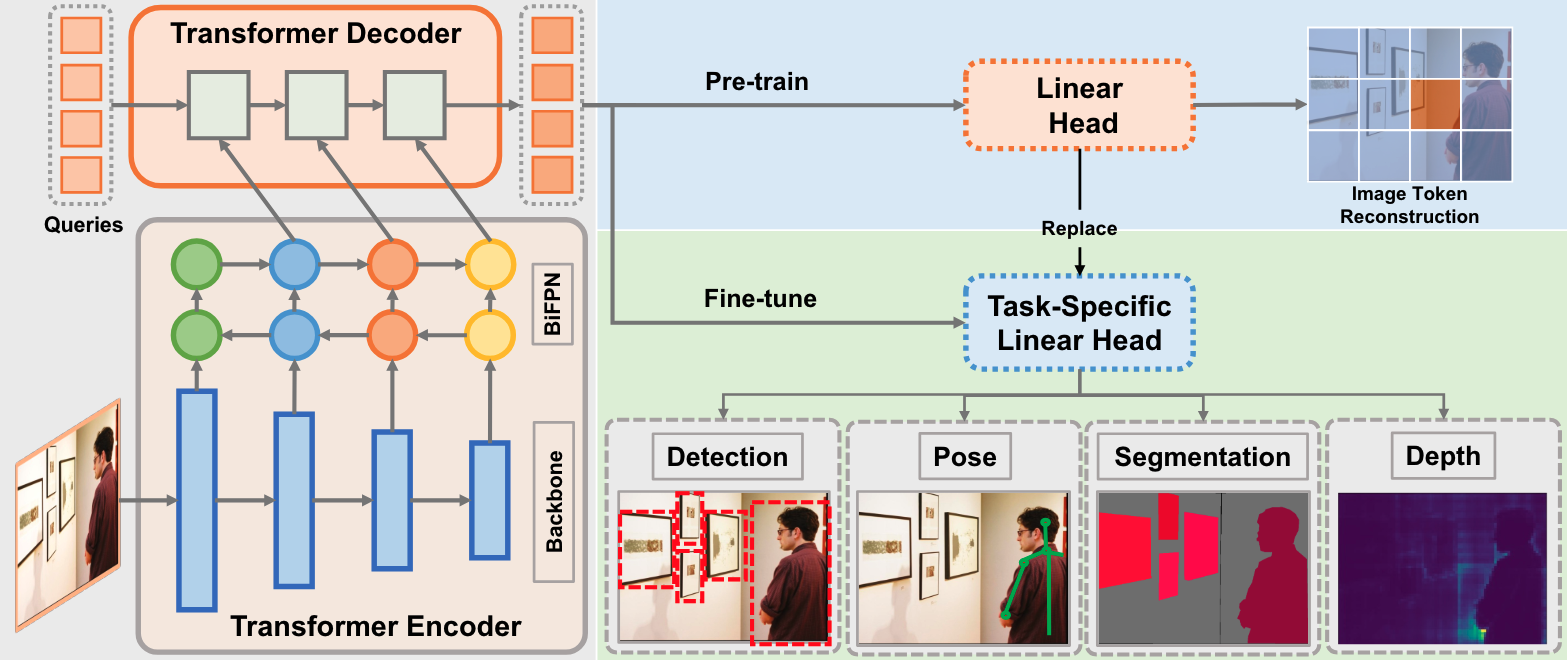
Jihao Liu, Jinliang Zheng, Yu Liu, Hongsheng Li CVPR, 2024 arxiv We proposes a GeneraLIst encoder-Decoder (GLID) pre-training method for better handling various downstream computer vision tasks. |
|
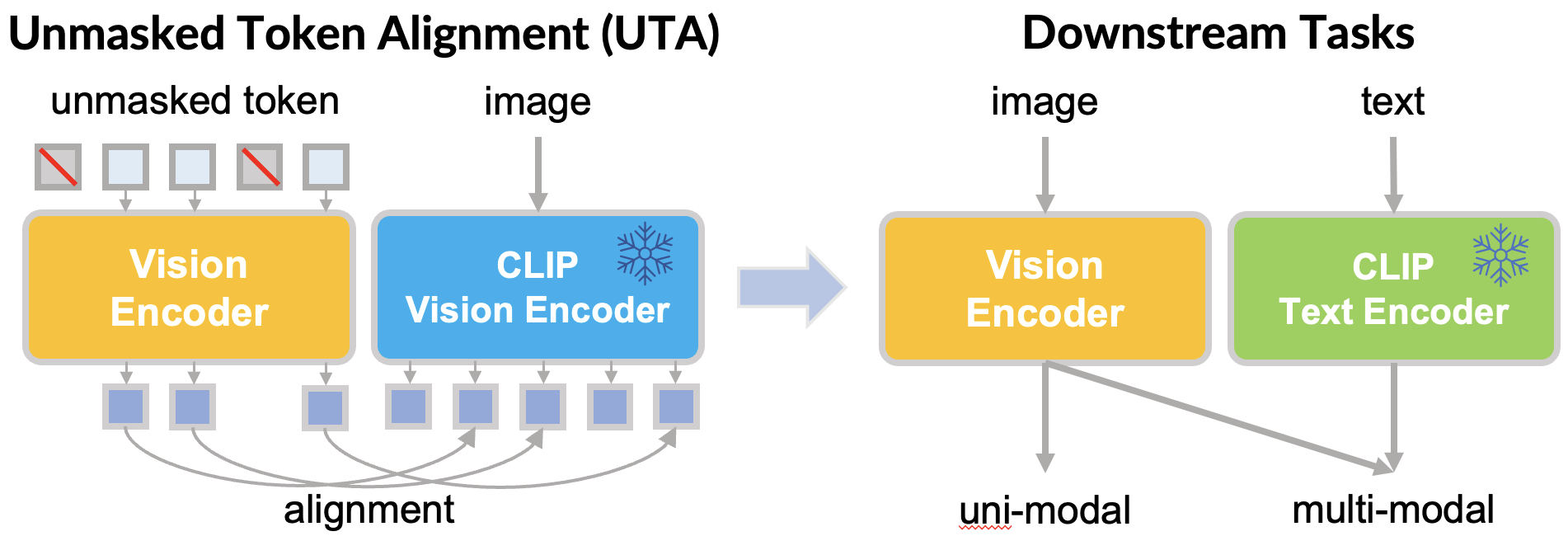
Jihao Liu, Jinliang Zheng, Boxiao Liu, Yu Liu, Hongsheng Li TMLR, 2024 paper / code We introduce Unmasked Token Alignment (UTA) for efficient visual-language representation learning. |
|
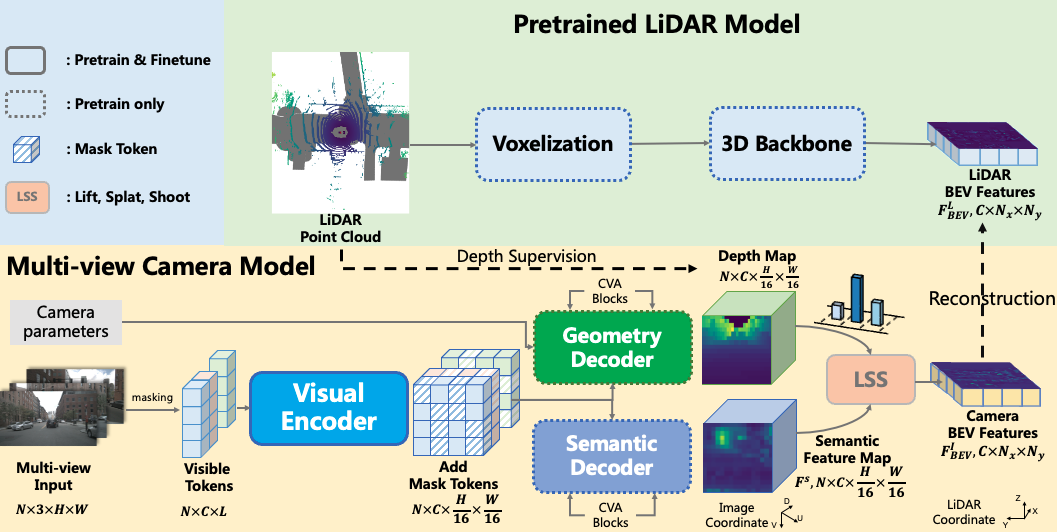
Jihao Liu, Tai Wang, Boxiao Liu, Qihang Zhang, Yu Liu, Hongsheng Li ICCV, 2023 arxiv / code We propose Geometry Enhanced Masked Image Modeling (GeoMIM) to transfer the knowledge of the LiDAR model in a pretrain-finetune paradigm for improving the multi-view camera-based 3D detection. |
|
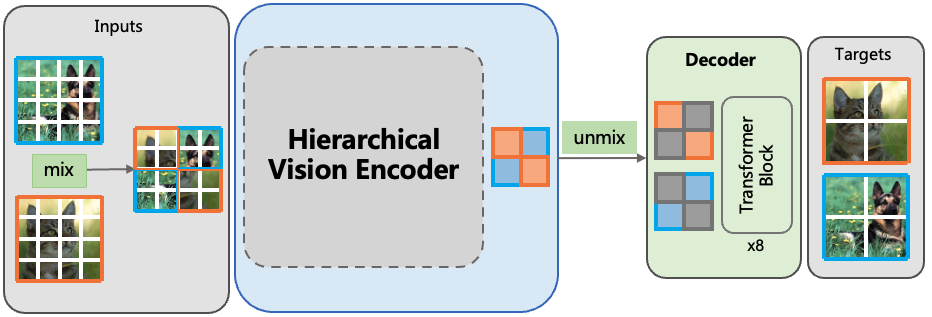
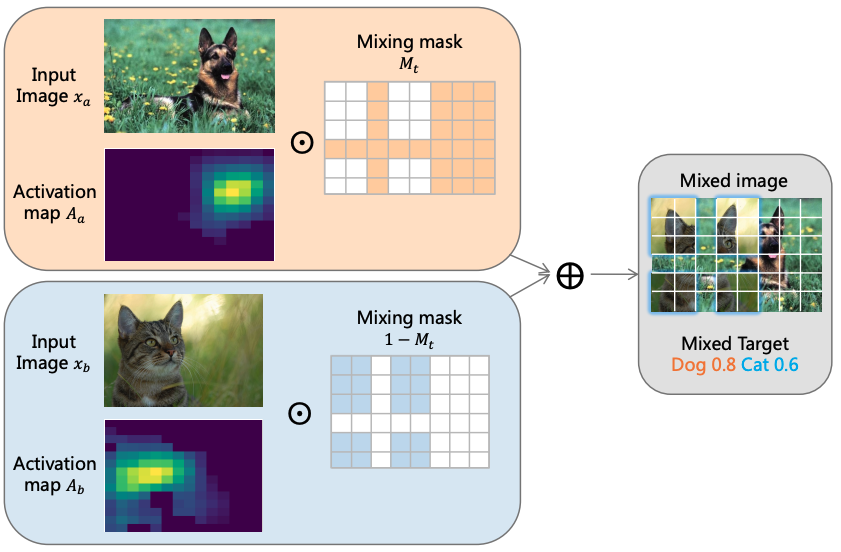
Jihao Liu, Xin Huang, Jinliang Zheng, Yu Liu, Hongsheng Li CVPR, 2023 arxiv / code We propose MixMAE for efficient pretraining of hierarchical vision transformers. |
|
Jihao Liu, Boxiao Liu, Hang Zhou, Hongsheng Li, Yu Liu ECCV, 2022 arxiv / code A token-level augmentation technique that can be well applied to training various transformer-based architectures. |
|
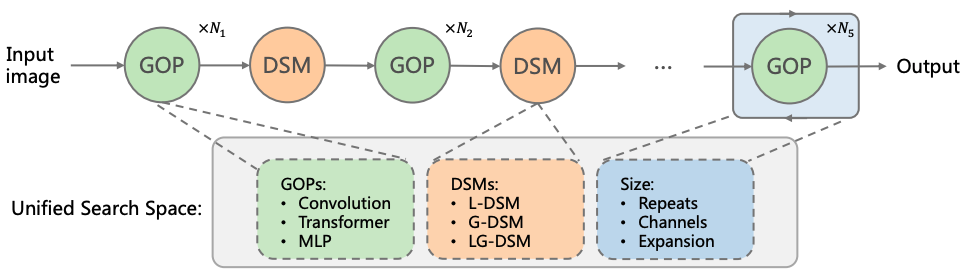
Jihao Liu, Xin Huang, Guanglu Song, Hongsheng Li, Yu Liu ECCV, 2022 arxiv / code A high-performance hybrid visual architectures through unified architecture search. |

|
Hang Zhou*, Jihao Liu*, Ziwei Liu, Yu Liu, Xiaogang Wang CVPR, 2020 arxiv / code Self-supervised approach for face rotation in the wild. |
|
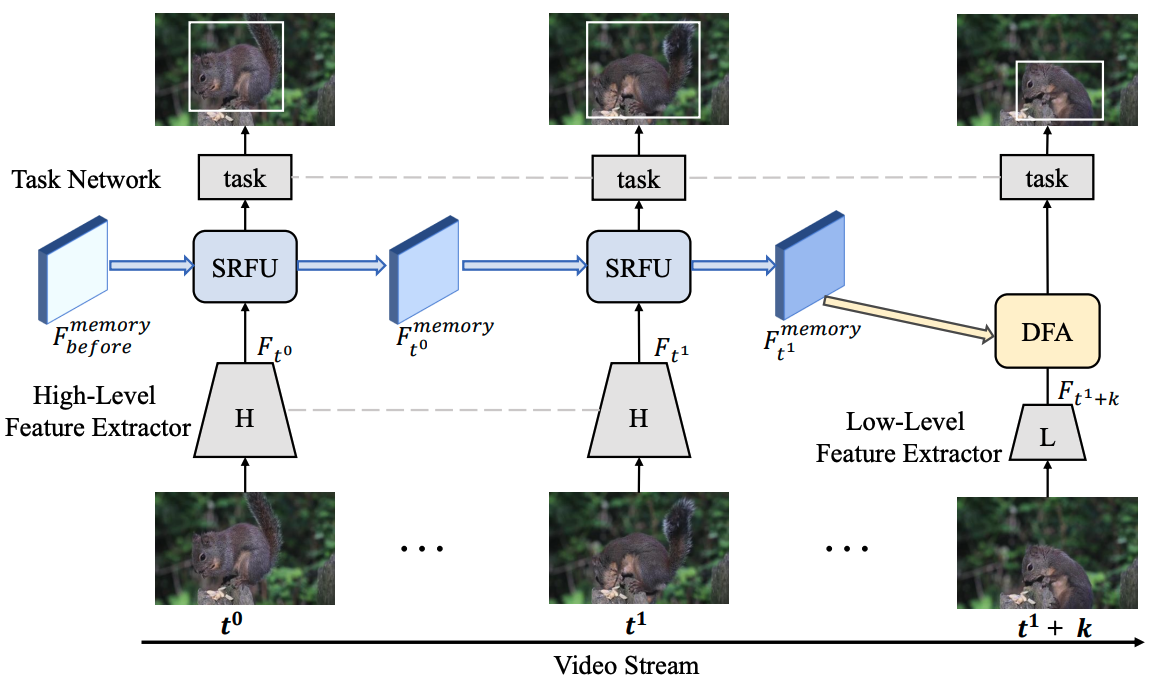
Zhengkai Jiang, Yu Liu, Ceyuan Yang, Jihao Liu, Peng Gao, Qian Zhang, Shiming Xiang, Chunhong Pan ECCV, 2020 arxiv / code We propose LSTS module to learn semantic-level correspondences among adjacent frame features accurately. |
|
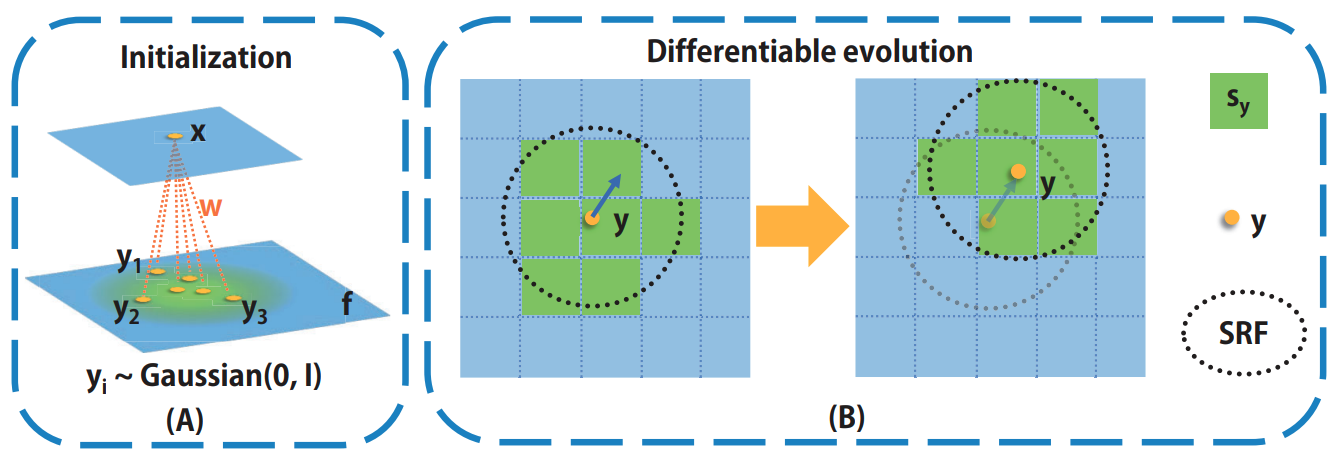
Yu Liu*, Jihao Liu*, Ailing Zeng, Xiaogang Wang ICCV, 2019 We proposes a differentiable kernel evolution (DKE) algorithm which can find a better layer-operator for the convolutional neural network. |
|
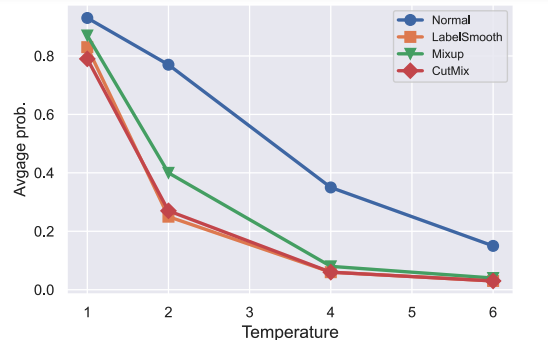
Jihao Liu, Jinliang Zheng, Boxiao Liu, Hongsheng Li, Yu Liu arxiv, 2022 arxiv We propose Meta Knowledge Distillation (MKD) to meta-learn the distillation with learnable meta temperature parameters. |
|
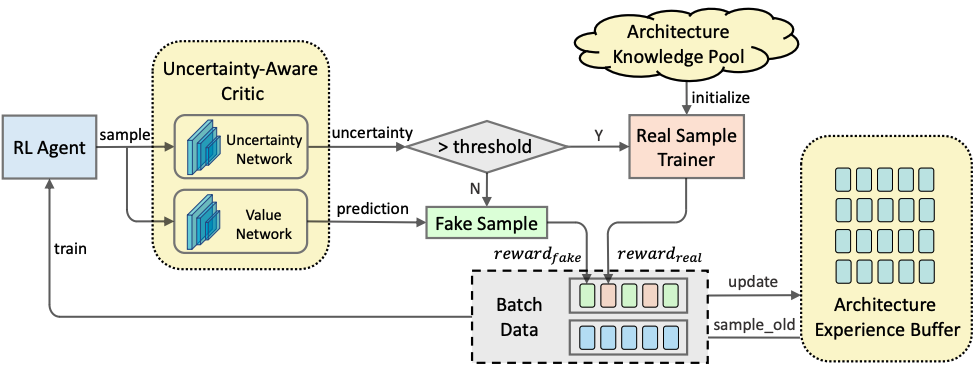
Jihao Liu, Ming Zhang, Yangting Sun, Boxiao Liu, Guanglu Song, Yu Liu, Hongsheng Li arxiv, 2021 arxiv We propose a general pipeline to accelerate the convergence of the rollout process as well as the RL process in NAS. |
|
|
|
|
|
|
|
The website template was borrowed from Jon Baron. |